i.equalcare x Chinese University of Hong Kong (Shenzhen)
The full paper was presented at the 2023 ICCNS (IEEE-Sponsored First International Conference on Computational Intelligence, Networks and Security). A pdf copy can be found below.
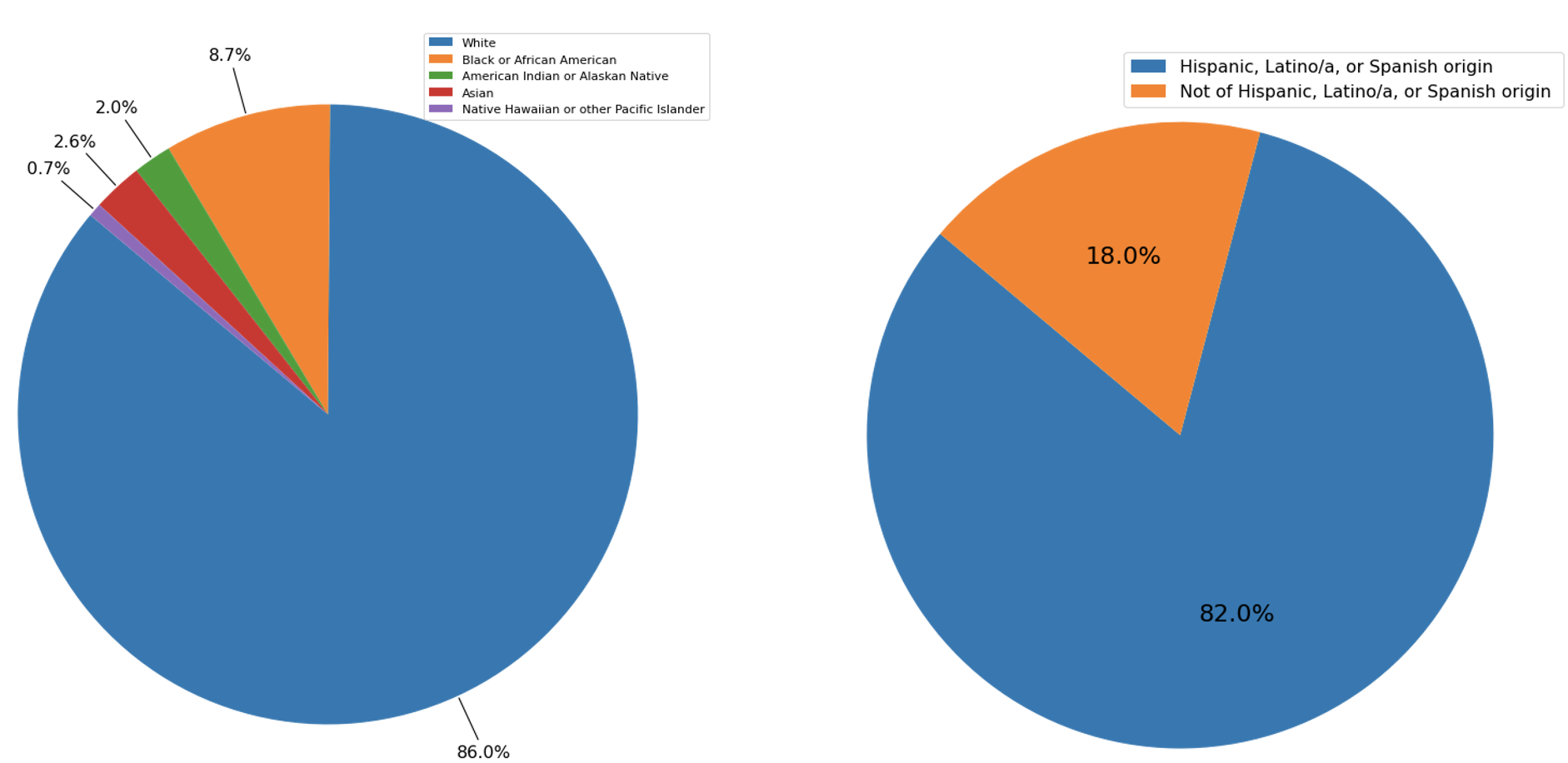
In this project, we use health survey data from the Centers for Disease Control and Prevention (CDC) to predict cardiovascular disease risk. Responses to this survey are collected from all territories of the US, and are imbalanced with respect to race/ethnicity due to the demographic composition of the US population.
Thus, we implement Fair Mixup, a data augmentation method (https://arxiv.org/abs/2103.06503) to make interpolated samples between groups and improve accuracy in respect to group fairness measurements (measured by demographic parity and equality of opportunity).
In the experiment, we compare three methods with a simple neural network architecture: Fair Mixup, GapReg basic fairness regularization, and without fairness regularization (WFR). A couple of our results for minority groups in the dataset are shown below with graphs showing average precision(AP) with demographic parity (DP) and equality of opportunity (EO).


From the results, we can see that with the Fair Mixup method, we can achieve a higher average precision while minimizing demographic parity. We can also achieve high precision at a low equality of opportunity value, compared to the method without any fairness regularization. Thus, Fair Mixup and data augmentation are viable strategies for improving both the generalization of the predictions and the overall accuracy of the model for underrepresented groups.
